

Explanations & Tutorials
Machine Learning Crash Course, Part II: Unsupervised Machine Learning
In this article, we take a look at two subdisciplines of machine learning: Unsupervised learning and deep learning.
In this article, we take a look at two subdisciplines of machine learning: Unsupervised learning and deep learning.
In part one of the machine learning crash course, we introduced the field of supervised machine learning (ML) by walking through popular algorithms like linear regression and logistic regression. But supervised learning is just one of the many types of algorithms in the vast machine learning / artificial intelligence space. In this article, we take a look at two other subdisciplines: Unsupervised learning and deep learning. Let’s get started.
When performing supervised learning, our datasets consisted of labeled examples. In the linear regression example, we had TV advertising data labeled with the amount of sales generated. In an unsupervised learning problem, input variables are provided withoutoutput labels. One reason people use unsupervised learning is to find patterns of behavior in the dataset. Let’s look at a concrete example.
A common unsupervised learning algorithm is K-means clustering. This algorithm finds groups (“clusters”) of data points that share similar variable values. The diagram below illustrates the end result of applying this program. It has successfully identified three clusters.
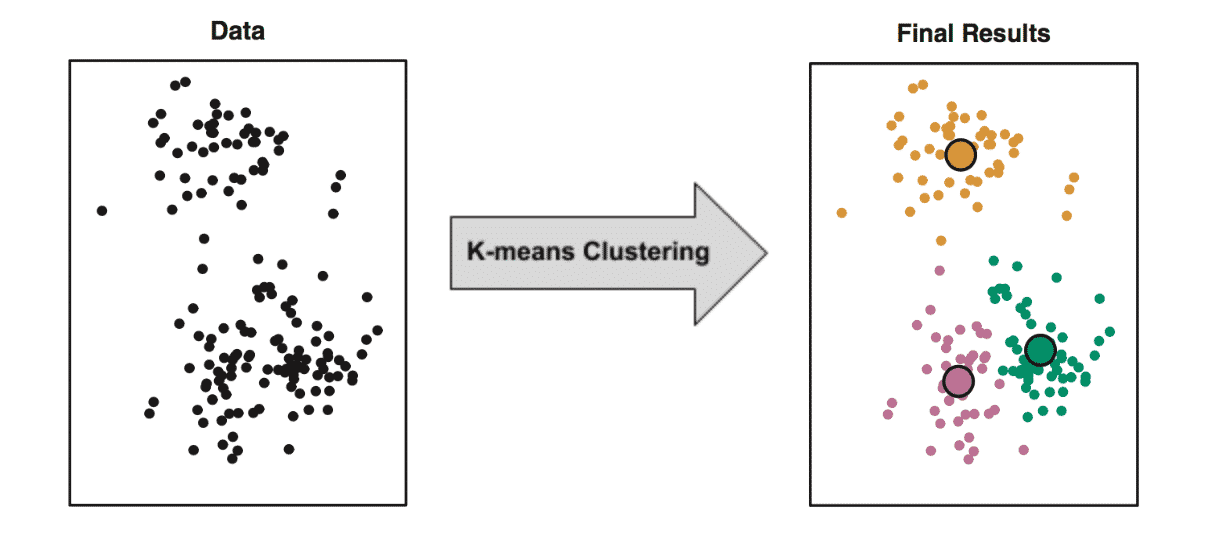
One obvious question is ‘why is this useful?’ Suppose that this data came from a retail store, where the dots represent individual customers. The x-axis represents the time they entered the store (say, 9am – 9pm), and the y-axis represents their purchase price. The company might want to examine the yellow cluster in more detail and figure out the types of products they are buying. With that knowledge, the store could target those customers more effectively and achieve higher profits.
In this simple example, one could easily identify the clusters just by looking at the graph. But if you are working with hundreds or thousands of data points, this algorithm can save you a lot of time. Additionally, we only had two variables to keep track of (time and purchase price). But what if we had many variables (e.g. time they entered store, time they exited store, purchase price, customer age, number of items bought, etc.)? It then becomes impossible to visualize all the variables in a graph, so you will definitely need to use K-means clustering.
You’ve probably heard the phrase ‘deep learning’ in the media. Technically, deep learning is a type of ML because machine learning is defined as the ability to learn without being explicitly programmed, a characteristic that is certainly true of DL algorithms. However, they are much more powerful than traditional machine learning algorithms.

Most DL algorithms use neural networks as their underlying architecture. The photo above is a diagram of neural network with four layers with a few nodes (2-4) per layer. The word ‘deep’ comes from the fact that AI developers usually use networks with tens or hundreds of layers (and tens or hundreds of nodes per layer).
So what makes deep learning so much more powerful than traditional machine learning? The answer is that deep neural networks are great at feature extraction: the process of figuring out what aspects of a dataset are actually useful for making predictions.
For example, suppose you were writing an algorithm to perform image recognition, the ability to identify objects (i.e. ‘car’, ‘truck’, ‘bicycle’) in a photo. One feature of a photo might be the edges/silhouettes in the photo, like the outline of the car shown in the diagram below.

Deep learning algorithms are smart enough to identify such complex features on their own, whereas ML algorithms cannot. This is one of the reason why DL has become so popular these days. The ability to learn features allows us to solve very complex problems such as autonomous driving, language translation and speech recognition.
Join companies like CarMax, Discount Tire, Yamaha, and TPI Composites who have selected Leverege to launch innovative IoT-enabled asset management applications to optimize operations, increase revenue, and delight customers.

Thanks for submitting your information. Our team will be in touch soon.

Skip the complexity of IoT and get highly configurable IoT applications tailored to your business.








.svg)

